이 글은 “LMM - 대규모 멀티모달 모델의 이해와 적용” 강의의 상세 내용입니다. 강의 개요는 여기에서 확인할 수 있습니다.
이 내용을 슬라이드로 보려면 프레젠테이션 모드를 이용하세요.
LMM - 대규모 멀티모달 모델 시연
https://drive.google.com/drive/folders/11c3T36h_NXSgvCJ9A6oPi6kvQnH2YaIq
Part 1 — Large Language Model
LLM이란
LLM(Large Language Model)은 텍스트를 입력받아 텍스트를 출력하는 대규모 언어 모델입니다.

%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
A["text\n(채팅 입력)"] --> B["Model"] --> C["text\n(채팅 답변)"]
style A fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style B fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style C fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
“Large"의 의미
“Large"는 모델 자체가 크다는 뜻입니다. 구체적으로 모델의 파라미터 수가 많다는 것을 의미합니다.
Ollama에서 모델들을 살펴보면 같은 모델이라도 크기 차이가 있습니다.
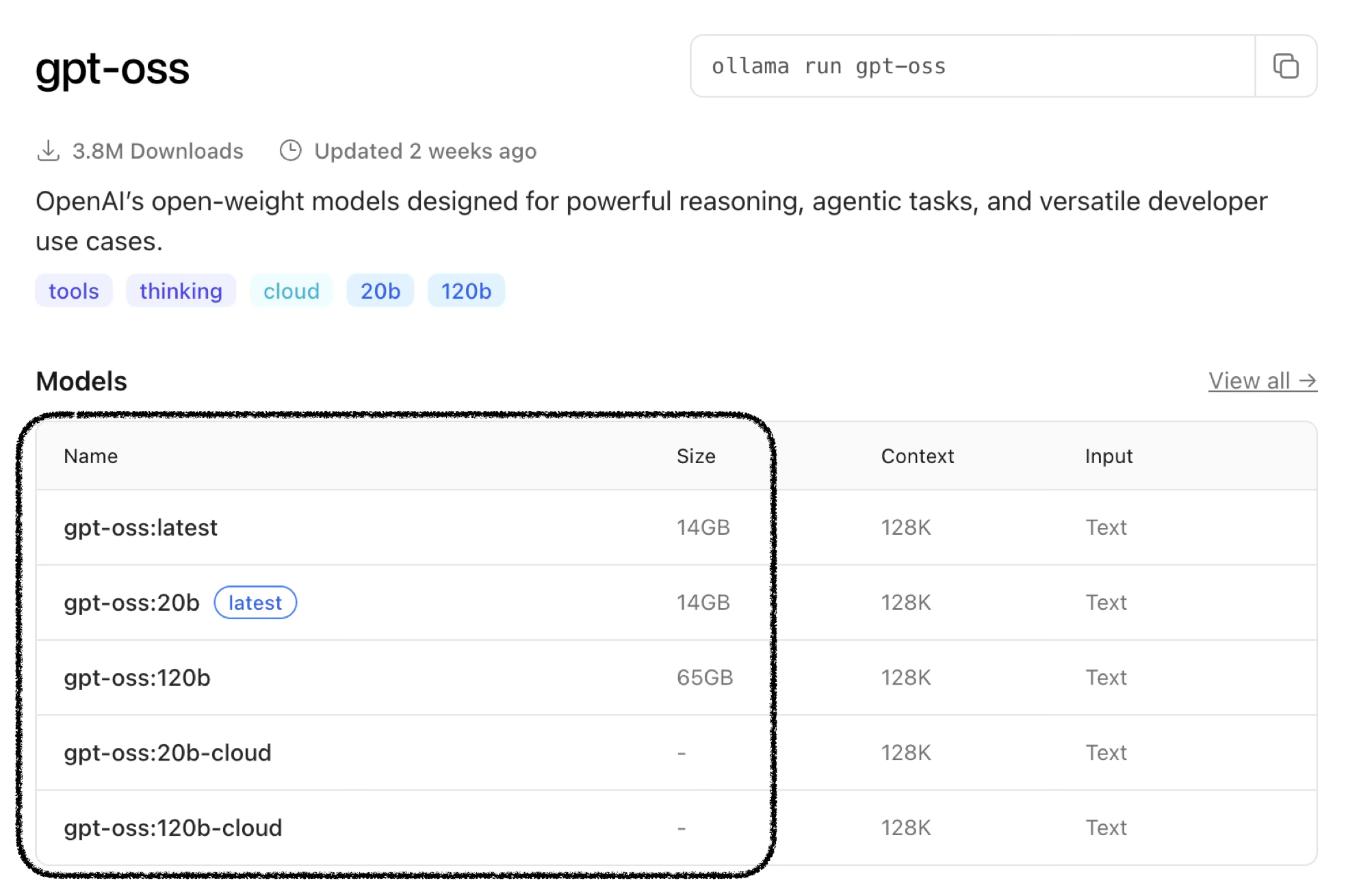
gpt-oss 모델 예시:
| Name | Size | Context | Input |
|---|
| gpt-oss:20b | 14GB | 128K | Text |
| gpt-oss:120b | 65GB | 128K | Text |
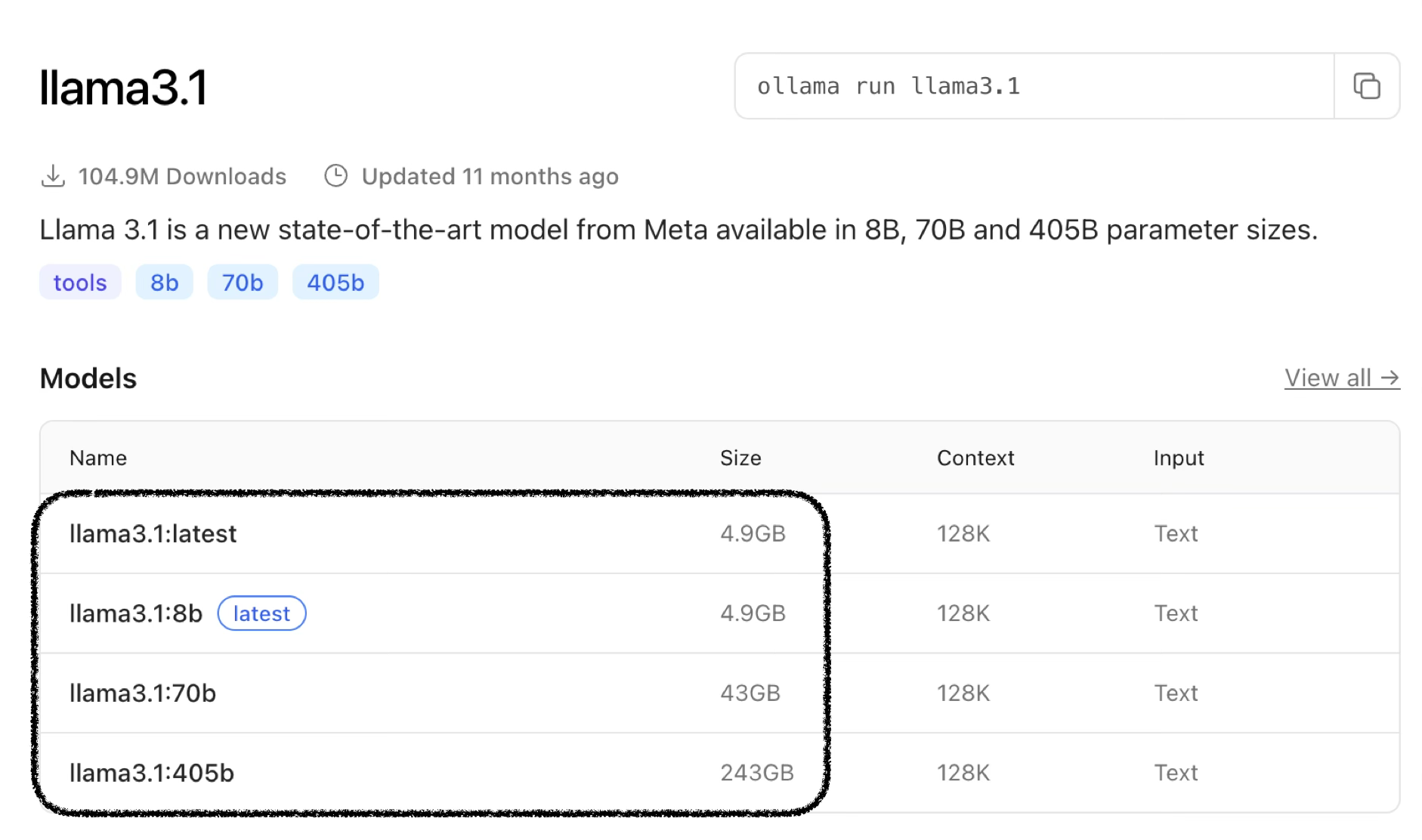
llama3.1 모델 예시:
| Name | Size | Context | Input |
|---|
| llama3.1:8b | 4.9GB | 128K | Text |
| llama3.1:70b | 43GB | 128K | Text |
| llama3.1:405b | 243GB | 128K | Text |
같은 모델인데 왜 크기 차이가 날까요? 파라미터 수가 다르기 때문입니다.
8b는 80억개, 70b는 700억개, 405b는 4050억개의 파라미터를 가집니다.
현재 대부분의 LLM은 Transformer 아키텍처에 기반을 두고 있습니다.
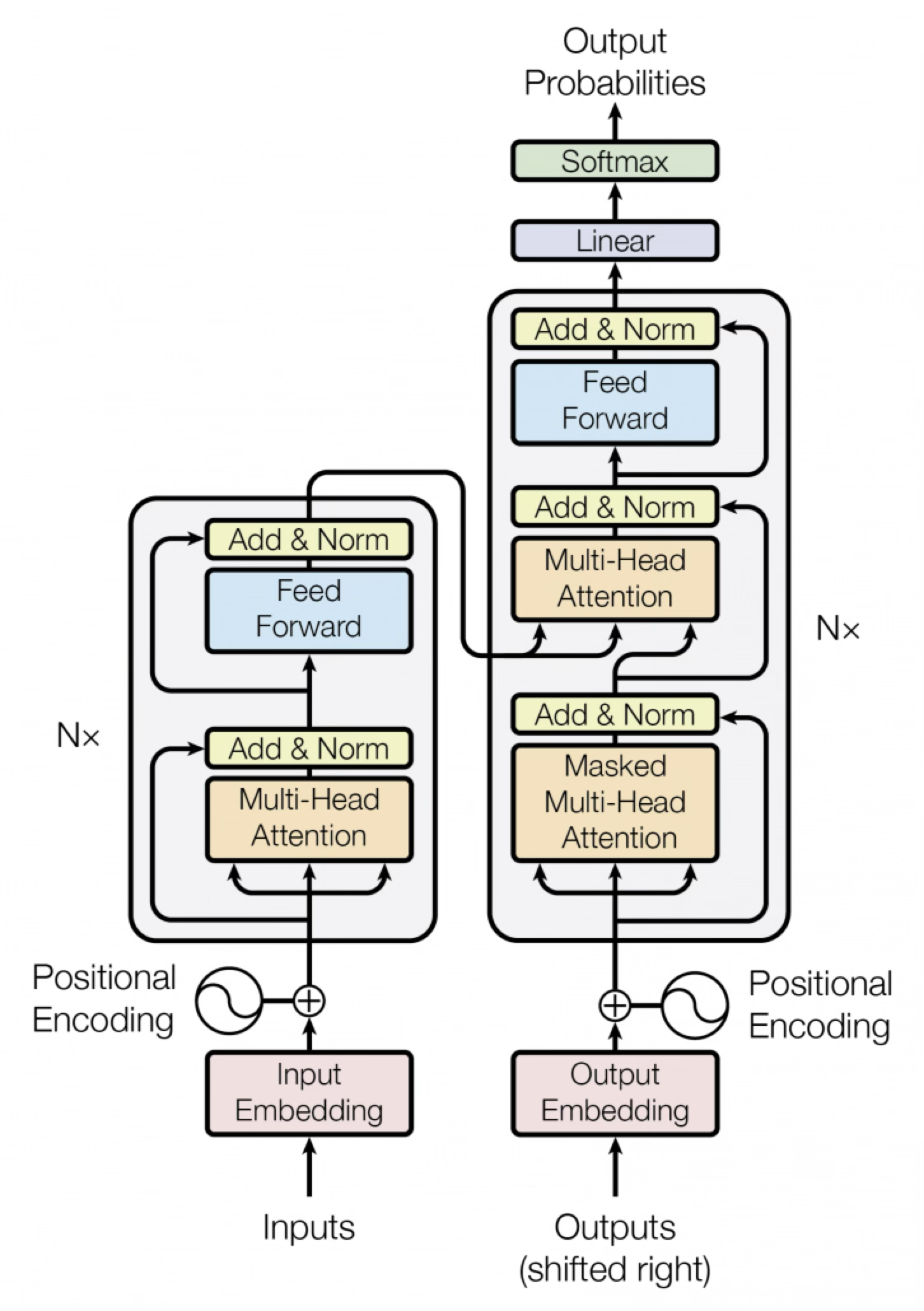
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart TB
subgraph Encoder["Encoder (Nx)"]
direction TB
IE["Input\nEmbedding"] --> PE1["+ Positional\nEncoding"]
PE1 --> MHA1["Multi-Head\nAttention"]
MHA1 --> AN1["Add & Norm"]
AN1 --> FF1["Feed\nForward"]
FF1 --> AN2["Add & Norm"]
end
subgraph Decoder["Decoder (Nx)"]
direction TB
OE["Output\nEmbedding"] --> PE2["+ Positional\nEncoding"]
PE2 --> MMHA["Masked\nMulti-Head\nAttention"]
MMHA --> AN3["Add & Norm"]
AN3 --> MHA2["Multi-Head\nAttention"]
MHA2 --> AN4["Add & Norm"]
AN4 --> FF2["Feed\nForward"]
FF2 --> AN5["Add & Norm"]
end
AN2 --> MHA2
AN5 --> LIN["Linear"]
LIN --> SM["Softmax"]
SM --> OUT["Output\nProbabilities"]
style IE fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style OE fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style PE1 fill:#f3e5f5,stroke:#ab47bc,stroke-width:2px,rx:10,ry:10
style PE2 fill:#f3e5f5,stroke:#ab47bc,stroke-width:2px,rx:10,ry:10
style MHA1 fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style MHA2 fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style MMHA fill:#ffe0b2,stroke:#ef6c00,stroke-width:2px,rx:10,ry:10
style AN1 fill:#e0f2f1,stroke:#00897b,stroke-width:1px,rx:10,ry:10
style AN2 fill:#e0f2f1,stroke:#00897b,stroke-width:1px,rx:10,ry:10
style AN3 fill:#e0f2f1,stroke:#00897b,stroke-width:1px,rx:10,ry:10
style AN4 fill:#e0f2f1,stroke:#00897b,stroke-width:1px,rx:10,ry:10
style AN5 fill:#e0f2f1,stroke:#00897b,stroke-width:1px,rx:10,ry:10
style FF1 fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style FF2 fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style LIN fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style SM fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style OUT fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style Encoder rx:15,ry:15
style Decoder rx:15,ry:15
Transformer 기반 모델 예시:
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT (Generative Pre-trained Transformer)
- T5 (Text-to-Text Transfer Transformer)
- ViT (Vision Transformer)
- CLIP (Contrastive Language–Image Pretraining)
- ALBERT (A Lite BERT)
이 Transformer 기반 모델은 텍스트에만 국한된 것이 아니라, 관계를 나타내는 형태면 어떤 데이터에도 적용이 가능합니다.
다만, Transformer의 Attention 메커니즘은 파라미터 수가 엄청나게 많으며, 따라서 학습을 위해 엄청나게 많은 데이터가 필요합니다.
Local LLM
이런 큰 모델을 로컬에서 돌리는 것이 Local LLM입니다.
Local LLM을 지원하는 프로그램들:
중요한 점:
- 제공되는 것은 전부 학습이 완료된(pre-trained) 모델입니다
- 로컬에서 돌려지는 부분은 “추론(inference)” 부분만 실행됩니다
- 실제로 학습(training)을 하려면 엄청나게 커다란 하드웨어(GPU 클러스터)가 필요합니다
Part 2 — Multimodal Model
LLM에서 LMM으로
텍스트 입력, 출력으로 진행되는 LLM.

%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
subgraph LLM["LLM"]
T1["text"] --> M1["Model"] --> T2["text"]
end
subgraph LMM["LMM"]
TI["text\nimage\naudio\n..."] --> M2["Model"] --> TO["text\nimage\naudio\n..."]
end
LLM -- "진화" --> LMM
style T1 fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style M1 fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style T2 fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style TI fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style M2 fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style TO fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style LLM rx:15,ry:15
style LMM rx:15,ry:15
멀티모달 데이터는 텍스트, 이미지, 음성 등 여러 형태의 데이터를 포함하며, 이러한 데이터를 통합하여 처리함으로써 더 풍부한 정보를 얻을 수 있습니다.
멀티모달의 장점
| 장점 | 설명 |
|---|
| 정보의 통합 | 서로 다른 형태의 데이터를 결합하여 더 깊이 있는 분석과 이해가 가능 |
| 정확성 향상 | 다양한 데이터 소스를 결합함으로써 모델의 예측 정확성 향상 |
| 응용 범위 확대 | 자율주행, 의료 진단, 고객 서비스 등 다양한 산업 분야에서 활용 |
복잡한 이미지 해석 예시

이미지만 입력한 경우:
“번화한 도시 거리에 여러 사람들이 걸어가고 있고, 자동차들이 도로를 지나가고 있습니다.”
이미지+텍스트(질문)를 함께 입력한 경우:
질문: “교통 표지판의 종류와 위치를 자세히 설명해주세요.”
답변: “이 도시 사진에는 총 3개의 주요 교통 표지판이 있습니다. 오른쪽 상단에 빨간색 정지 표지판, 도로 중앙에 노란색 주의 표지판, 왼쪽 하단에 파란색 주차 안내 표지판이 보입니다.”
멀티모달 모델 아키텍처 예시
이미지(VGG16)와 텍스트(Dense)를 결합하는 간단한 멀티모달 모델:
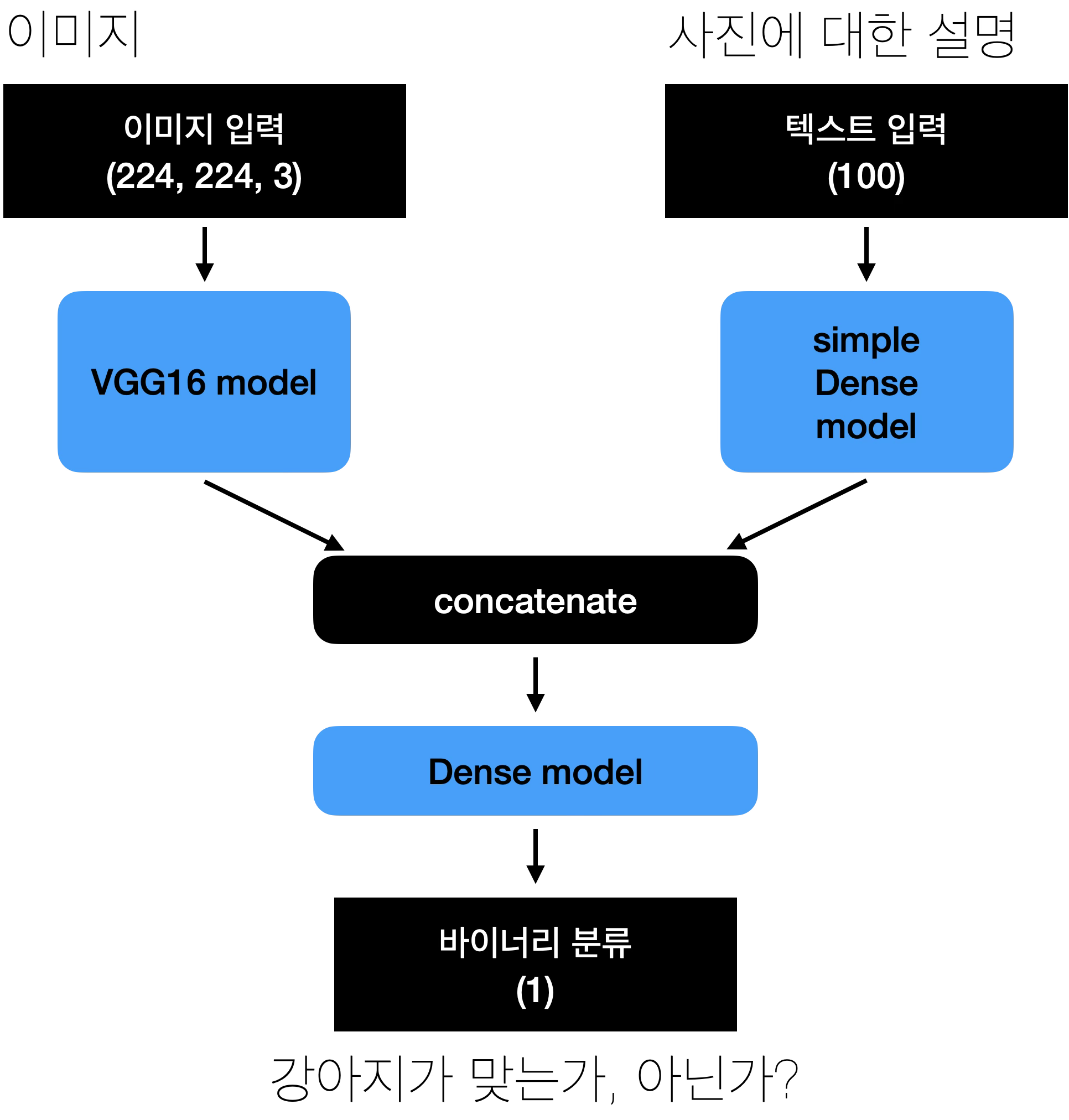
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart TB
IMG["이미지 입력\n(224, 224, 3)"] --> VGG["VGG16 model"]
TXT["텍스트 입력\n(100)"] --> DNS["simple Dense model"]
VGG --> CAT["concatenate"]
DNS --> CAT
CAT --> DM["Dense model"]
DM --> OUT["바이너리 분류 (1)\n강아지가 맞는가?"]
style IMG fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style TXT fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style VGG fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style DNS fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style CAT fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style DM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style OUT fill:#e0e0e0,stroke:#616161,stroke-width:2px,rx:10,ry:10
과연 어떤 것이 더 잘 학습할까요?
| 접근 | 설명 |
|---|
| VGG16 이미지 분류 | 이미지 자체에 대해서만 학습 |
| 텍스트 분류 | 텍스트에 대해서만 학습 |
| 멀티모달 (이미지+텍스트) | 같은 모델이지만, 학습은 둘 다에 맞춰 진행 |
멀티모달 접근이 단일 모달보다 더 풍부한 맥락을 활용할 수 있습니다.
코드 예시 (TensorFlow/Keras)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Concatenate, Embedding, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.applications import VGG16
# 이미지 입력 및 처리
image_input = Input(shape=(224, 224, 3), name='image_input')
base_model = VGG16(weights='imagenet', include_top=False, input_tensor=image_input)
x = Flatten()(base_model.output)
image_features = Dense(256, activation='relu')(x)
# 텍스트 입력 및 처리
text_input = Input(shape=(100,), name='text_input')
text_features = Embedding(input_dim=5000, output_dim=256, input_length=100)(text_input)
text_features = Flatten()(text_features)
text_features = Dense(256, activation='relu')(text_features)
# 멀티모달 융합
combined_features = Concatenate()([image_features, text_features])
output = Dense(1, activation='sigmoid')(combined_features)
# 모델 생성
model = Model(inputs=[image_input, text_input], outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
|
데이터 융합 방식
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart TB
subgraph HF["Hybrid Fusion"]
direction TB
HI["이미지"] --> HIM["이미지 모델"]
HT["텍스트"] --> HTM["텍스트 모델"]
HIM --> HC1["중간 결합"]
HTM --> HC1
HC1 --> HM["통합 처리"]
HM --> HO["출력"]
end
subgraph LF["Late Fusion"]
direction TB
LI["이미지"] --> LIM["이미지 모델"]
LT["텍스트"] --> LTM["텍스트 모델"]
LIM --> LC["결합"]
LTM --> LC
LC --> LO["출력"]
end
subgraph EF["Early Fusion"]
direction TB
EI["이미지"] --> EC["결합"]
ET["텍스트"] --> EC
EC --> EM["통합 모델"] --> EO["출력"]
end
style EI fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style ET fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style EC fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style EM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style EO fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style LI fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style LT fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style LIM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style LTM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style LC fill:#eceff1,stroke:#546e7a,stroke-width:2px,rx:10,ry:10
style LO fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style HI fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style HT fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style HIM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style HTM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style HC1 fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style HM fill:#b3e5fc,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style HO fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style EF rx:15,ry:15
style LF rx:15,ry:15
style HF rx:15,ry:15
| 방식 | 장점 | 단점 |
|---|
| Early Fusion | 데이터 간 상호작용을 초기에 반영 | 차원이 커지고, 각 모달리티 특성 반영 부족 |
| Late Fusion | 각 모달리티의 특성을 독립적으로 반영 | 모달리티 간 상호작용 반영 부족 |
| Hybrid Fusion | 양쪽 장점 결합 | 설계 복잡도 증가 |
기본 Multi Modal 모델 - 모델 생성 코드
https://colab.research.google.com/drive/12jm2SfjBy-3VppVisylaDiAdKcBd0d32
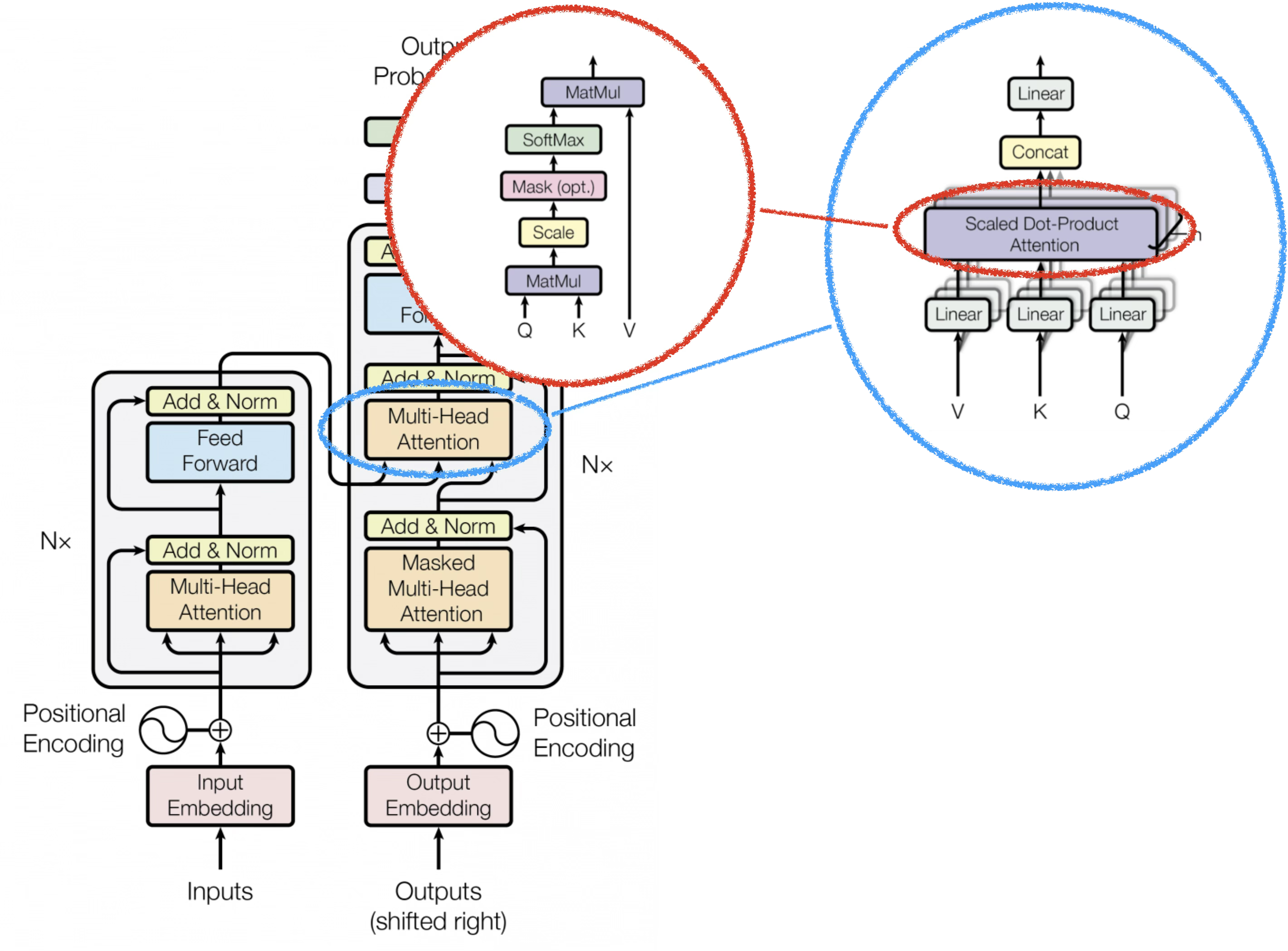
Transformer 모델의 핵심은 Attention 메커니즘입니다.
입력 시퀀스 내의 관계를 학습하는 Self-Attention과,
서로 다른 시퀀스 간의 관계를 학습하는 Cross-Attention으로 구성됩니다.
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
subgraph SDPA_detail["Scaled Dot-Product Attention"]
direction TB
MM1["MatMul(Q,K)"] --> SC["Scale"] --> MK["Mask (opt.)"] --> SF["SoftMax"] --> MM2["MatMul(result, V)"]
end
subgraph MHA["Multi-Head Attention"]
direction TB
Q["Q"] --> LQ["Linear"]
K["K"] --> LK["Linear"]
V["V"] --> LV["Linear"]
LQ --> SDPA["Scaled Dot-Product\nAttention"]
LK --> SDPA
LV --> SDPA
end
SDPA_detail ~~~ MHA
style Q fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style K fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style V fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style LQ fill:#ffe0b2,stroke:#ef6c00,stroke-width:1px,rx:10,ry:10
style LK fill:#b3e5fc,stroke:#0288d1,stroke-width:1px,rx:10,ry:10
style LV fill:#e8f5e9,stroke:#43a047,stroke-width:1px,rx:10,ry:10
style SDPA fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style MM1 fill:#eceff1,stroke:#546e7a,stroke-width:1px,rx:10,ry:10
style SC fill:#eceff1,stroke:#546e7a,stroke-width:1px,rx:10,ry:10
style MK fill:#eceff1,stroke:#546e7a,stroke-width:1px,rx:10,ry:10
style SF fill:#e8eaf6,stroke:#5c6bc0,stroke-width:1px,rx:10,ry:10
style MM2 fill:#eceff1,stroke:#546e7a,stroke-width:1px,rx:10,ry:10
style MHA rx:15,ry:15
style SDPA_detail rx:15,ry:15
텍스트에서의 Attention
1단계 - 문장:
한국어: “안녕하세요, 오늘 날씨는 정말 좋습니다.”
영어: “Hello, the weather is really nice today.”
2단계 - 토큰화 및 임베딩:
한국어 토큰: 안녕하세요 / , / 오늘 / 날씨 / 는 / 정말 / 좋습니다 / . → 8개 토큰 → v1~v8
영어 토큰: Hello / , / the / weather / is / really / nice / today / . → 9개 토큰 → v9~v17
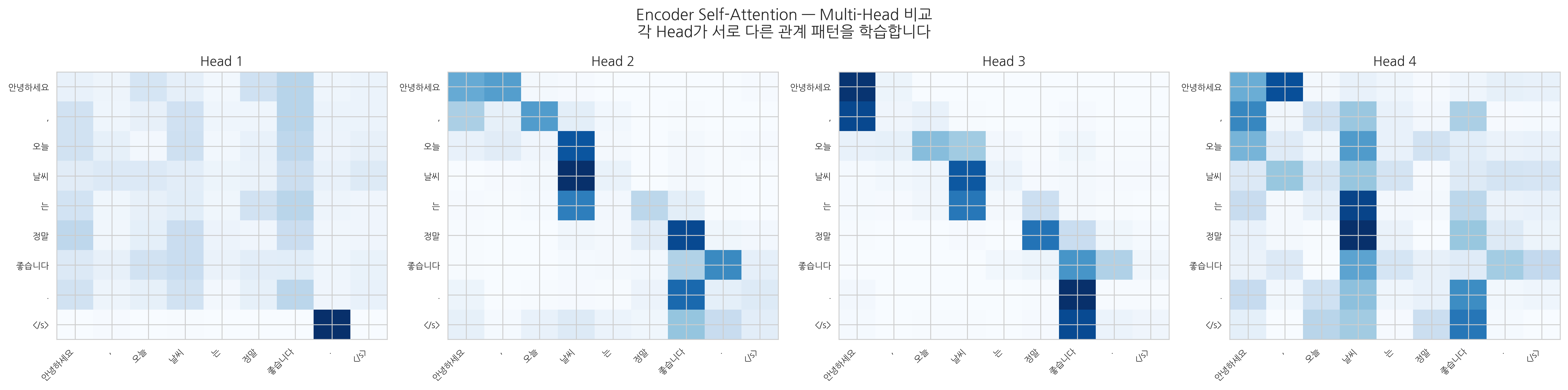
3단계 - QKV 가중치 학습 (Attention):
8개 입력 토큰 x 9개 출력 토큰 = 72가지 경우에 대해서 관계를 계산합니다.
각 칸의 값은 “입력 토큰 vi가 출력 토큰 vj에 얼마나 주의(attention)를 기울이는가"를 나타냅니다.
아래 인터랙티브 데모에서 셀을 클릭하여 확인해보세요.
문장이 길어지면 길어질수록, 계산량이 많아집니다.
이미지에서의 Attention
Transformer는 이미지에도 적용 가능합니다. 텍스트의 단어 간 관계처럼, 이미지에서는 픽셀과 픽셀 사이의 관계를 학습합니다.
계산량 폭발 문제
256x256 이미지의 경우:
- 입력: 256x256 = 65,536 픽셀
- 출력: 256x256 = 65,536 픽셀
- 관계 조합: 65,536 x 65,536 = 4,294,967,296 (약 42억개)
텍스트(72개)에 비해 이미지(42억개)는 계산량이 압도적으로 많습니다.
해결 방법
이미지에 직접 Self-Attention을 적용하기엔 너무 크기 때문에,
subsampling 및 convolution을 거쳐 크기를 줄인 다음 Self-Attention을 적용합니다. (예: Conformer 아키텍처)
Dense vs Convolution vs Self-Attention 비교
각 레이어를 클릭하여 연결 패턴의 차이를 확인해보세요.
| 레이어 | 연결 범위 | 학습 대상 | 계산량 |
|---|
| Dense | 모든 입력 → 모든 출력 | 가중치 | 중간 |
| Convolution | 주변 N개 → 출력 | 커널 패턴 | 적음 |
| Self-Attention | 모든 입력 간 관계 | 관계 가중치(QKV) | 많음 |
기본 Transformer 모델
https://colab.research.google.com/drive/1j0AM731RDRcw81u6vtr1DH83ImWeTZOu
Part 4 — CLIP 모델
CLIP 개요
CLIP (Contrastive Language-Image Pretraining): OpenAI에서 개발한 이미지-텍스트 유사도 모델.
아래 데모에서 이미지와 텍스트를 선택하여 유사도 점수를 확인해보세요.
- 1에 가까울수록 이미지와 텍스트가 잘 일치
- 고양이 사진 + ‘고양이 사진’ → 높은 점수
- 고양이 사진 + ‘자동차 사진’ → 낮은 점수
데모 노트북: CLIP_model.ipynb — COCO 데이터셋으로 CLIP 유사도를 직접 테스트해볼 수 있습니다.
COCO 데이터셋 시연 결과
Cat 카테고리 (COCO 이미지 ID: 416256):

| 텍스트 | 유사도 점수 |
|---|
| ‘동물 사진’ | 0.1865 |
| ‘강아지가 앉아있는 모습’ | 0.0435 |
| ‘고양이가 앉아있는 모습’ | 0.0290 |
| ‘고양이 사진’ | 0.7410 |
Dog 카테고리 (COCO 이미지 ID: 329219):

| 텍스트 | 유사도 점수 |
|---|
| ‘동물 사진’ | ~0.30 |
| ‘고양이가 앉아있는 모습’ | ~0.07 |
| ‘강아지가 앉아있는 모습’ | ~0.12 |
| ‘강아지 사진’ | ~0.47 |
CLIP 모델 구조
1
2
3
4
5
| model_name = "openai/clip-vit-base-patch32"
model = TFCLIPModel.from_pretrained(model_name)
model.summary()
# Total params: 151,277,313 (577.08 MB)
|
- 파라미터: 약 1.5억개
- TFCLIPTextTransformer + TFCLIPVisionTransformer 로 구성
학습 방법: 대조 학습 (Contrastive Learning)
관련 쌍은 가까이, 비관련 쌍은 멀리 — “학습 시작” 버튼을 눌러 임베딩 공간에서의 변화를 확인하세요.
- 인터넷에서 수집한 대규모 이미지-텍스트 쌍 데이터셋으로 학습
- 대조 손실(contrastive loss): 관련 쌍의 유사성 최대화, 비관련 쌍의 유사성 최소화
SigLIP 2: CLIP의 후속 표준 (2025)
CLIP이 멀티모달 비전 인코더의 시작이었다면, SigLIP 2는 현재의 표준입니다.
| 비교 | CLIP | SigLIP 2 |
|---|
| 개발 | OpenAI | Google (2025.02) |
| 손실 함수 | Softmax contrastive | Sigmoid loss |
| 학습 방식 | 대조 학습만 | 대조 + captioning + self-distillation |
| 적용 | 별도 아키텍처 | CLIP과 동일 아키텍처 → 가중치만 교체 (Drop-in) |
| 채택 | 과거 표준 | Phi-4 Vision 등 최신 모델 채택 |
CLIP 모델
https://colab.research.google.com/drive/1vdznbhCYSFNOy3GMec9kZrOGxQcJRXTg
SigLIP 모델 (Sigmoid)
https://colab.research.google.com/drive/1En9IcpJ0XHCKZoXatmkE-AuTd0niMWaU
SigLIP 모델 (Softmax)
https://colab.research.google.com/drive/1vIMFZblhLyHJ3MQwr2GmBl-ugaEoOGje
Part 5 — BLIP-2 모델
BLIP-2 개요
BLIP-2 (Bootstrapping Language-Image Pre-training 2): Salesforce에서 개발. (2023) 각 단계 탭을 클릭하여 데이터 흐름을 확인하세요.
데모 노트북: BLIP-2 Demo.ipynb — Image Captioning, VQA, Q-Former 시각화 등을 직접 실행해볼 수 있습니다.
2단계 학습 상세
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
subgraph Stage1["1단계: Vision-Language Representation"]
direction TB
S1_IMG["Image\nEncoder ❄️"] --> S1_QF["Q-Former"]
S1_Q["Learned\nQueries"] --> S1_QF
S1_TXT["Text"] --> S1_QF
end
subgraph Stage2["2단계: Vision-to-Language Generation"]
direction TB
S2_IMG["Image\nEncoder ❄️"] --> S2_QF["Q-Former"]
S2_Q["Learned\nQueries"] --> S2_QF
S2_QF --> S2_FC["Fully\nConnected"]
S2_FC --> S2_LLM["LLM ❄️"]
S2_LLM --> S2_OUT["Output Text"]
end
Stage1 -- "학습된 Q-Former" --> Stage2
style S1_IMG fill:#e3f2fd,stroke:#90a4ae,stroke-width:1px,rx:10,ry:10
style S1_QF fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style S1_Q fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style S1_TXT fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style S2_IMG fill:#e3f2fd,stroke:#90a4ae,stroke-width:1px,rx:10,ry:10
style S2_QF fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style S2_Q fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style S2_FC fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style S2_LLM fill:#e3f2fd,stroke:#90a4ae,stroke-width:1px,rx:10,ry:10
style S2_OUT fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style Stage1 rx:15,ry:15
style Stage2 rx:15,ry:15
1단계: 이미지 인코더(ViT-L/14)와 Q-Former로 이미지-텍스트 정렬 학습
- 32개의 Learned Queries가 이미지에서 무엇을 추출할지 학습
- 3가지 학습 목표: Image-Text Matching / Image-Grounded Text Generation / Contrastive Learning
2단계: Q-Former 출력을 LLM에 연결하여 텍스트 생성 학습
- Q-Former와 FC 레이어만 학습 (이미지 인코더와 LLM은 frozen)
효율성
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
pie title BLIP-2 파라미터 학습 비율
"학습되는 부분 (Q-Former + FC)" : 190
"Frozen (Image Encoder + LLM)" : 3010
전체 3.2B 파라미터 중 190M만 학습 (6%) — 기존 모델을 재활용하여 효율적
Adapter 방식에서 Native Multimodal로 (2025~)
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart TB
subgraph Adapter["Adapter 방식 (BLIP-2, 2023)"]
direction LR
A_IMG["Frozen\n이미지 인코더"] --> A_QF["Adapter\n(Q-Former)"] --> A_LLM["Frozen\nLLM"]
end
subgraph Native["Native Multimodal (Llama 4, 2025)"]
direction LR
N_IN["이미지 토큰\n+\n텍스트 토큰"] --> N_TF["통합\nTransformer"] --> N_OUT["출력"]
end
Adapter -- "2025~ 전환" --> Native
style A_IMG fill:#e3f2fd,stroke:#90a4ae,stroke-width:1px,rx:10,ry:10
style A_QF fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
style A_LLM fill:#e3f2fd,stroke:#90a4ae,stroke-width:1px,rx:10,ry:10
style N_IN fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style N_TF fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style N_OUT fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style Adapter rx:15,ry:15
style Native rx:15,ry:15
| 모델 | 방식 | 특징 |
|---|
| BLIP-2 (2023) | Adapter | Frozen encoder + Q-Former + Frozen LLM |
| Llama 4 (Meta, 2025) | Native Multimodal | MetaCLIP + Early Fusion + MoE |
| GPT-4o (OpenAI, 2024) | Native Multimodal | 통합 멀티모달 토큰화 |
Native Multimodal의 장점: 정보 병목 해소, 첫 레이어부터 cross-modal 이해 가능
BLIP2 모델
https://colab.research.google.com/drive/1EZxyRM6z4GW6fG5NTykhZuCTTPKxKLzM
Part 6 — Stable Diffusion과 이미지 생성
Denoising 개념

%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
A["원본 이미지"] -- "+노이즈" --> B["노이즈 이미지"]
B -- "Denoising 모델" --> C["복원된 이미지"]
D["순수 노이즈"] -- "Denoising 모델" --> E["생성된 이미지!"]
style A fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style B fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style C fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style D fill:#cfd8dc,stroke:#78909c,stroke-width:2px,rx:10,ry:10
style E fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
이 원리를 역으로 이용하면, 순수한 노이즈에서 시작하여 의미 있는 이미지를 생성할 수 있습니다.
아래 데모에서 슬라이더를 움직여 denoising 과정을 단계별로 확인해보세요.
Stable Diffusion 아키텍처
프롬프트를 선택하고 “생성 시작"을 눌러 파이프라인의 각 단계를 확인하세요.

| 컴포넌트 | 역할 |
|---|
| VAE | 이미지 ↔ Latent Space 압축/복원 (512x512 → 64x64) |
| U-Net | 실제 denoising 수행, 텍스트 조건을 Cross-Attention으로 주입 |
| CLIP Text Encoder | 텍스트 프롬프트를 임베딩 벡터로 변환 |
데모 노트북: Stable Diffusion Demo.ipynb — 프롬프트, 가이던스 스케일, 부정 프롬프트 등을 변경하며 이미지를 생성해볼 수 있습니다.
Autoregressive 이미지 생성 (2025)
2025년, GPT-4o가 Diffusion 없이 이미지를 생성하면서 패러다임이 전환되었습니다. “동시 생성 시작” 버튼을 눌러 두 방식의 차이를 확인하세요.
지브리풍 바이럴 사례 (2025.03)
- GPT-4o의 이미지 생성 기능 출시 직후
- 72시간 동안 1.3억 사용자가 7억장의 이미지 생성
- AI 생성 이미지의 저작권·윤리 문제가 사회적 이슈로 부각
Stable Diffusion 모델
https://colab.research.google.com/drive/1ggdT0sOW68jPU4YKPoNWSN0trYw2I1fa
Part 7 — 최신 트렌드와 미래 방향
MoE (Mixture of Experts)
기존 모델은 입력이 들어오면 모든 파라미터를 사용합니다.
MoE는 다릅니다. “새 입력 보내기” 버튼을 눌러 라우터가 어떤 Expert를 선택하는지 확인하세요.
| 항목 | 값 |
|---|
| 전체 파라미터 | ~400B |
| 활성 파라미터 | 17B (128개 Expert 중 일부만 활성화) |
| 멀티모달 | MoE + Early Fusion |
| 비전 인코더 | MetaCLIP 기반 |
“Large"를 유지하면서도 추론 비용을 크게 절감 → 로컬에서도 더 큰 모델 가능
Omni-Modal: 텍스트+이미지+오디오+비디오 통합
입력 모달리티를 선택하고 Thinker-Talker 아키텍처의 동작을 확인하세요.
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart TB
IN["입력\n(텍스트 / 이미지 / 오디오 / 비디오)"]
IN --> TH["Thinker (LLM)"]
TH --> TXT_OUT["텍스트 출력"]
TH -- "hidden states" --> TK["Talker (음성 생성)"]
TK --> VOICE_OUT["음성 출력"]
style TH fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style TK fill:#ffccbc,stroke:#e64a19,stroke-width:2px,rx:10,ry:10
style TXT_OUT fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style VOICE_OUT fill:#fff9c4,stroke:#f9a825,stroke-width:2px,rx:10,ry:10
Qwen2.5-Omni (Alibaba, 2025.03): Thinker-Talker 아키텍처로 텍스트를 생각하면서 동시에 말하는 구조
비디오 이해 + Grounding
모델이 “이 영상에서 사람은 어디에 있는가?“라는 질문에 대해 바운딩박스 좌표 (x1, y1, x2, y2) 로 정확한 위치를 출력합니다.
아래 데모에서 질문을 선택하여 각 프레임의 바운딩박스를 확인하세요.
활용 가능한 모델 (RTX 3090, 24GB)
| 모델 | FP16 VRAM | Grounding | 비디오 |
|---|
| Qwen2.5-VL-7B | ~15GB | bbox 출력 | 멀티프레임 지원 |
| Molmo-7B | ~14-16GB | (x,y) 좌표 | 프레임별 처리 |
| InternVL2-8B | ~16GB | bbox | 멀티프레임 |
| Florence-2 | ~2-4GB | bbox+세그멘테이션 | 이미지만 |
윤리와 저작권
- 저작권: 학습 데이터에 포함된 이미지/텍스트의 저작권 문제
- 딥페이크: 사실적인 이미지/영상 생성으로 인한 위험
- 편향: 학습 데이터의 편향이 모델 출력에 반영
- 지브리 사례: 특정 작가/스튜디오의 스타일을 무단 복제하는 것의 윤리적 문제
Part 8 — 시연: Qwen2.5-VL 비디오 Grounding
시연 환경
| 항목 | 구성 |
|---|
| 모델 | Qwen2.5-VL-7B-Instruct |
| 하드웨어 | RTX 3090 (24GB VRAM) 원격 서버 |
| VRAM 사용량 | FP16 ~15GB |
| 프레임워크 | Transformers + Qwen-VL-Utils |
데모 노트북: Qwen2.5-VL Demo.ipynb — 이미지 Grounding, 비디오 이해, 비디오 Grounding을 직접 실행해볼 수 있습니다.
시연 내용
%%{init: {'theme':'base','themeVariables':{'primaryColor':'#e3f2fd','primaryBorderColor':'#90caf9','lineColor':'#546e7a','textColor':'#333','mainBkg':'#fafafa','nodeBorder':'#90a4ae','clusterBkg':'#f5f5f5','clusterBorder':'#bdbdbd'}}}%%
flowchart LR
subgraph Demo1["1. 이미지 Grounding"]
I1["이미지 + 질문"] --> M1["Qwen2.5-VL"] --> B1["바운딩박스\n좌표 출력"]
end
subgraph Demo2["2. 비디오 이해"]
V2["비디오 프레임\n(1~8장)"] --> M2["Qwen2.5-VL"] --> D2["영상 내용\n설명"]
end
subgraph Demo3["3. 비디오 Grounding"]
V3["비디오 프레임\n+ 추적 질문"] --> M3["Qwen2.5-VL"] --> T3["프레임별\nbbox 추적"]
end
Demo1 --> Demo2 --> Demo3
style I1 fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style M1 fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style B1 fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style V2 fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style M2 fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style D2 fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style V3 fill:#bbdefb,stroke:#1976d2,stroke-width:2px,rx:10,ry:10
style M3 fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,rx:10,ry:10
style T3 fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,rx:10,ry:10
style Demo1 rx:15,ry:15
style Demo2 rx:15,ry:15
style Demo3 rx:15,ry:15
시연 코드 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# 모델 로드
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
# 이미지 + 질문 입력
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/image.jpg"},
{"type": "text", "text": "이 이미지에서 사람의 위치를 바운딩박스 좌표로 알려주세요."},
],
}
]
# 추론
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs,
padding=True, return_tensors="pt").to("cuda")
output_ids = model.generate(**inputs, max_new_tokens=512)
output_text = processor.batch_decode(output_ids, skip_special_tokens=True)
|
핵심 관찰 포인트
- 같은 이미지라도 질문(텍스트)에 따라 다른 Grounding 결과
- 비디오 프레임 수에 따른 이해도 차이
- FP16 vs 4-bit 양자화 시 품질/속도 차이
- 한국어 질문 vs 영어 질문의 결과 차이
Qwen 2.5
https://colab.research.google.com/drive/1O-G-l0RIK_DJy6oVehZgySzH8r901P0a
전체 아키텍처 진화 요약
%%{init: {'theme':'base','themeVariables':{'cScale0':'#ddeef8','cScale1':'#fff9c4','cScale2':'#dceedd','cScale3':'#ddeef8','cScaleLabel0':'#2c3e50','cScaleLabel1':'#2c3e50','cScaleLabel2':'#2c3e50','cScaleLabel3':'#2c3e50','cScalePeer0':'#90bcd8','cScalePeer1':'#f9c825','cScalePeer2':'#66bb6a','cScalePeer3':'#90bcd8','cScaleInv0':'#90bcd8','cScaleInv1':'#f9c825','cScaleInv2':'#66bb6a','cScaleInv3':'#90bcd8'}}}%%
timeline
title 멀티모달 모델 진화
2021 : CLIP — 이미지-텍스트 유사도, Contrastive Learning
2023 : BLIP-2 — Q-Former Adapter, 6%만 학습
2024 : GPT-4o — Native Multimodal, 텍스트+이미지+오디오
2025 : SigLIP 2 — CLIP 후속 표준
: Qwen2.5-Omni — Thinker-Talker
: Autoregressive 이미지 생성 — 지브리 바이럴
: Llama 4 — MoE, 17B active / 400B total
참고 자료